Começaremos a trabalhar com duas ferramentas provavelmente já conhecidas: o produto interno e a norma. Em cursos de álgebra vetorial e geometria analítica temos contato com uma versão do produto interno e norma chamada de euclidiana ou canônica. No caso do espaço R2, o produto interno euclidiano entre os vetores x=(x1,x2) e y=(y1,y2) é dado por
Eles nos dão em R2 e R3 uma importante ferramenta de análise geométrica, que permite relacionar ângulos e distâncias entre vetores.
A ideia agora é generalizarmos os conceitos de produto interno e norma, considerando um espaço vetorial qualquer. Possuindo espaços vetoriais munidos de produto interno, poderemos definir uma importante transformação linear, chamada de adjunta.
O produto interno, em um sentido geral, é definido como uma função entre vetores de um espaço que obedece algumas propriedades.
Note que as condições de aditividade e homogeneidade juntas formam uma condição de linearidade na primeira entrada. Com a condição de simetria, temos na verdade a linearidade nas duas entradas. Por isso, um produto interno é dito bilinear.
De maneira análoga ao que foi feito no exemplo, verifica-se que
A partir de todo produto interno podemos definir uma norma. Normas funcionam como métricas nos espaços vetoriais, medindo o comprimento ou “intensidade” dos vetores, além das distâncias entre eles.
Assim como no caso do produto interno, a definição de norma pode ser generalizada de maneira que qualquer função que atenda certas propriedades caracterize uma norma, mesmo que esta não esteja diretamente relacionada com um produto interno[1]. No caso das normas do tipo da Definição 7.3 (Norma induzida pelo produto interno), as quais voltaremos nossa atenção, essas propriedades são “herdadas” do produto interno. Uma dessas heranças imediatas é que ∥v∥=0 se, e somente se, v=0.
Adiante, consideraremos que ∥⋅∥ é uma norma induzida por produto interno em V.
Demonstração 7.5
∥v∥=0⟺⟨v,v⟩=0⟺⟨v,v⟩=0⟺v=0(pois o produto interno eˊ positivo-definido).
A alcunha de “Teorema de Pitágoras” fica clara quando consideramos o caso particular em que V=R2 (neste caso, ortogonalidade entre dois vetores equivale ao ângulo entre eles ser de 90 graus), onde o vetor u+v cumpre o papel de hipotenusa e os vetores u e v de catetos.
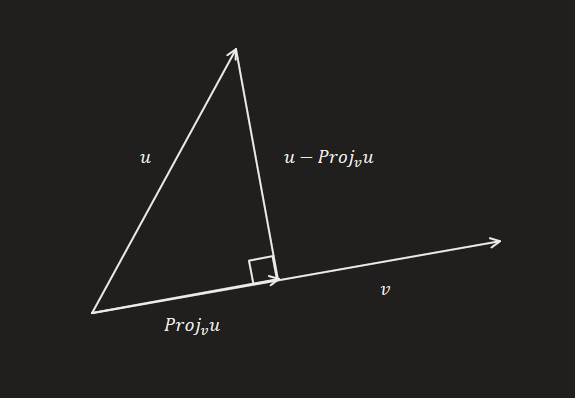
Note que o vetor projeção é um múltiplo escalar do vetor sobre o qual se projeta.
Note que, consequentemente, para qualquer vetor u, dado um vetor v não nulo podemos escrever o vetor u como a soma w+Projvu, onde w é um vetor ortogonal a v. Essa decomposição de u clarifica bem a seguinte interpretação geométrica que temos sobre esses vetores:
Relação geométrica entre os vetores.
O vetor projeção possui muitos usos na Álgebra Linear, mas um dos principais é provar a Desigualdade de Cauchy-Schwarz, uma das mais importantes desigualdades da matemática.
Demonstração 7.11
Para o caso em que v=0, é evidente que vale a igualdade:
Suponha que v=0. Logo, como discutido anteriormente, podemos decompor o vetor u na soma w+Projvu, onde w é um vetor ortogonal a v e, em particular, é ortogonal a Projvu (que é um múltiplo escalar de v). Sendo assim, veja que ∥u∥2=∥w+Projvu∥2. Então, utilizando Propriedade 7.8 Teorema de Pitágoras temos
Com isso, note que ∥u∥2≥∥v∥2⟨u,v⟩2 (pois ∥w∥2≥0), de onde obtemos ⟨u,v⟩2≤∥u∥2⋅∥v∥2. Extraindo a raiz quadrada em ambos os lados obtemos a desigualdade de Cauchy-Schwarz (lembre-se que a norma de qualquer vetor é sempre não negativa, logo é igual ao seu módulo).
Observe que vale a desigualdade se, e somente se, w=0. Ou seja, quando u=Projvu (u é um múltiplo escalar de v).
Onde a desigualdade é obtida utilizando Teorema 7.11 (Cauchy-Schwarz) em ∥u∥∥v∥ (lembre-se que se um número real é maior ou igual ao módulo de outro, ele será maior ou igual ao próprio número sem módulo).
Especificamente, uma lista (v1,…vn) de vetores em V é ortonormal quando ⟨vj,vk⟩=0 para j=k e ⟨vj,vk⟩=1 para j=k (note que isso implica que ∥vj∥=1 para todo vj na lista).
Um exemplo imediato de vetores ortonormais é a base canônica de Rn, considerando o produto interno e a norma canônicos.
Demonstração 7.14
Separemos o vetor a1v1+⋯+anvn em dois vetores, a1v1 e a2v2+…anvn. Utilizando o fato que (v1,…,vn) é ortonormal obtemos
Logo, os vetores a1v1 e a2v2+⋯+anvn também são ortogonais. Em particular, podemos aplicar Propriedade 7.8 Teorema de Pitágoras para eles, obtendo que
Agora, decompomos a2v2+⋯+anvn em a2v2 e a3v3+…anvn. Com uma análise análoga, temos que esses vetores também são ortogonais. Seguindo esse processo, com uma aplicação sucessiva de Propriedade 7.8 Teorema de Pitágoras, obtemos
O importante resultado a seguir mostra que dada qualquer lista de vetores linearmente independentes é possível encontrar uma lista ortonormal que gera o mesmo subespaço que tal lista dada.
A demonstração desse teorema é feita fornecendo um procedimento para encontrar tal lista ortonormal, o qual é denominado Processo de Gram-Schmidt ou Algoritmo de Gram-Schmidt.
Demonstração 7.18 (Processo de Gram-Schmidt)
Dada a lista linearmente independente (v1,…,vn), começamos fazendo u1=∥v1∥v1, um vetor de norma unitária que satisfaz Teorema 7.18 (Gram-Schmidt) para j=1. O processo de escolha de u2,…,un é feito indutivamente, da seguinte forma:
Como (v1,…,vn) é linearmente independente, vj não pertence ao espaço gerado por (v1,…,vj−1), implicando que vj não pertence ao espaço gerado por (u1,…,uj−1) (uma vez que vale span(v1,…,vj−1)=span(u1,…,uj−1)). Isso nos garante que vj=⟨vj,u1⟩u1+⋯+⟨vj,uj−1⟩uj−1 e, portanto, não estamos dividindo por zero na definição de uj, que é então um vetor de norma unitária. Agora, note que para 1≤k<j tem-se
Provando que (u1,…,uj) é ortonormal. Observe que, da definição de uj, temos que vj∈span(u1,…,uj). Por outro lado, temos também que span(v1,…,vj−1)=span(u1,…,uj−1), logo
No entanto, uma vez que tanto (v1,…,vj) e (u1,…,uj) são linearmente independentes, ambos os subespaços acima possuem dimensão igual a j, concluindo que devem ser iguais (pois um está contido no outro e possuem mesma dimensão). Dessa forma, construímos uma lista ortonormal tal que vale Teorema 7.18 (Gram-Schmidt).
Demonstração 7.19
Dada uma base desse espaço, que é uma lista linearmente independente, pelo Teorema 7.18 (Gram-Schmidt) existe uma lista ortonormal que também gera esse espaço. Além disso, essa lista é linearmente independente (pelo Corolário 7.15). Logo, é uma base ortonormal desse espaço.
Demonstração 7.20
Seja (u1,…,um) uma lista ortonormal de V, pelo Teorema 2.22 (Vetores LI podem ser estendidos em uma base) ela pode ser estendida em uma base (u1,…,um,v1,…,vn) de V. Aplicando o processo de Gram-Schmidt (descrito em Demonstração 7.18 (Processo de Gram-Schmidt)) nessa base, é produzida uma base ortonormal de V. Mas, note que pela maneira como é realizado o processo e considerando que (u1,…,um) já é ortonormal, tal base ortonormal produzida será da forma (u1,…,um,w1,…,wm), isto é, os vetores u1,…,um são preservados pelo processo. Portanto, no fim o que foi feito foi estender a lista ortonormal em uma base ortonormal de V.
O fato de w ser ortogonal a todos os ej implica que w é ortogonal a todos os vetores em U (pois os ej formam uma base de U). Logo, w∈U⊥. Sendo assim, escrevemos v=u+w, com u∈U e w∈U⊥, para um vetor v arbitrário de V, o que mostra que V=U+U⊥.
Para completar a prova, suponha u∈U∩U⊥. Note que, por um lado, u∈U⊥ e, portanto, é ortogonal a todo vetor em U. Mas, por outro lado, u∈U, implicando que u é ortogonal a si mesmo, ou seja
Mas isso faz com que u=0 (lembre-se do item 1 de Definição 7.1 (Produto interno)). Portanto, U∩U⊥={0}, concluindo que V=U⊕U⊥.
Demonstração 7.23
Começamos mostrando U⊆(U⊥)⊥. Seja u∈U, pela definição de U⊥ temos que ⟨u,v⟩=0 para todo v∈U⊥. Logo, u é ortogonal a todo vetor em U⊥, implicando que u∈(U⊥)⊥.
Para mostrar (U⊥)⊥⊆U, suponha v∈(U⊥)⊥. Como, em particular, v∈V, Teorema 7.22 garante que podemos escrever v=u+w, com u∈U e w∈U⊥. Assim, temos v−u=w∈U⊥. Mas, note que temos v∈(U⊥)⊥ e u∈(U⊥)⊥ (pela inclusão U⊆(U⊥)⊥ provada anteriormente), logo, v−u∈U⊥∩(U⊥)⊥. Ou seja, isso nos diz que v−u é ortogonal a si mesmo (pelo mesmo raciocínio utilizado na demonstração de Teorema 7.22), implicando que v−u=0. Sendo assim, v=u∈U, mostrando que (U⊥)⊥⊆U e, consequentemente, a igualdade U=(U⊥)⊥.
Os principais exemplos de normas não induzidas por produto interno em Rn são a norma do infinito (ou norma do máximo), usualmente denotada por ∥⋅∥∞ e dada pela maior coordenada em módulo do vetor, e a norma da soma (ou norma 1), usualmente denotada por ∥⋅∥S e dada pela soma dos módulos das coordenadas.